栈基础
/栈
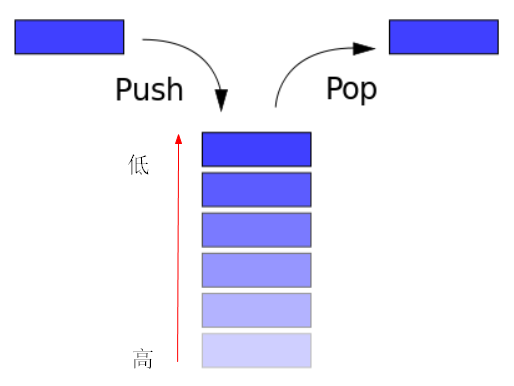
栈是一种典型的后进先出 (Last in First Out) 的数据结构,其操作主要有压栈 (push) 与出栈 (pop) 两种操作,两者都是对栈顶的操作。
每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。
程序的栈是从进程地址空间的高地址向低地址增长的,即从栈顶处增长。
栈帧
栈帧(Stack Frame)是利用EBP寄存器访问栈内局部变量、参数、函数返回地址等的手段,在程序中用于声明局部变量、调用函数等。
整个过程为:调用某函数时,先把用作基准点(函数起始地址)的ESP值保存到EBP并维持在函数内部。无论ESP的值如何变化,以EBP的值为基准能够准确安全访问到相关函数的局部变量、参数、返回地址等。
基本的栈帧结构如下:
1 | PUSH EBP |
具体的可参考之前的博文:栈帧
函数调用栈
函数调用栈是指程序运行时内存一段连续的区域,用来保存函数运行时的状态信息,包括函数参数与局部变量等。称之为“栈”是因为发生函数调用时,调用函数(caller)的状态被保存在栈内,被调用函数(callee)的状态被压入调用栈的栈顶;在函数调用结束时,栈顶的函数(callee)状态被弹出,栈顶恢复到调用函数(caller)的状态。函数调用栈在内存中从高地址向低地址生长,所以栈顶对应的内存地址在压栈时变小,退栈时变大。
函数调用发生和结束时调用栈的变化如图:
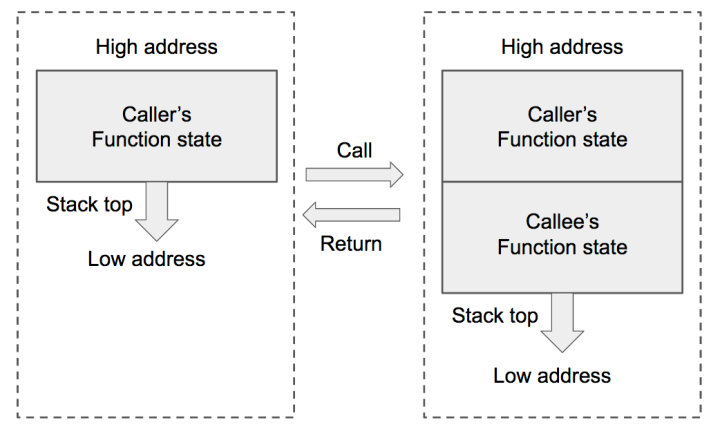
函数状态主要涉及三个寄存器——ESP,EBP,EIP。ESP用来在Push和Pop时存储函数调用栈的栈顶地址。EBP用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置,即栈帧作用。EIP用来存储即将执行的程序指令的地址,CPU依照 EIP的存储内容读取指令并执行,EIP随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
函数调用开始时的栈变化
下面让我们来看看发生函数调用开始时,栈顶函数状态以及上述寄存器的变化。
变化的核心任务是将调用函数(caller)的状态保存起来,同时创建被调用函数(callee)的状态。
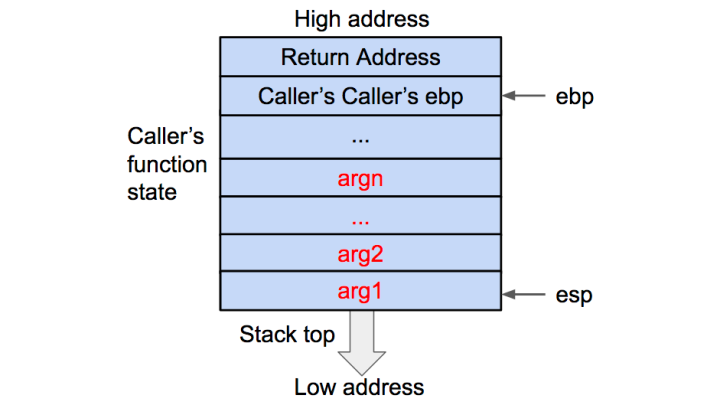
1、逆序Push被调函数的参数入栈
首先将被调用函数(callee)的参数按照逆序依次压入栈内。如果被调用函数(callee)不需要参数,则没有这一步骤。这些参数仍会保存在调用函数(caller)的函数状态内,之后压入栈内的数据都会作为被调用函数(callee)的函数状态来保存,如下图(注意一点就是,和开始的图的地址高低位方向不一样,现在是上面是高位下面是低位):
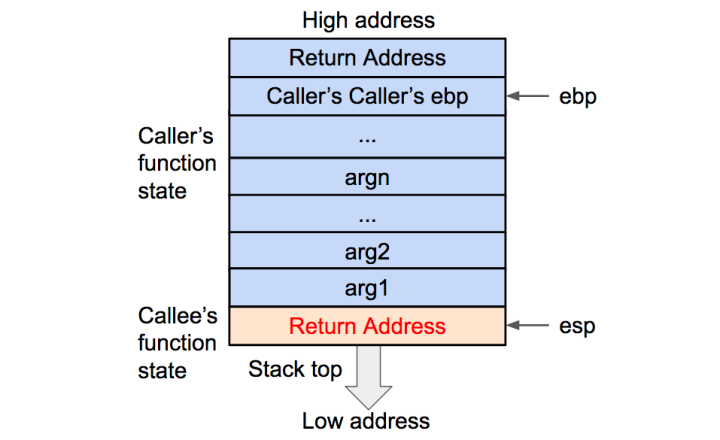
2、Push调用函数的下一条指令的地址入栈
然后将调用函数(caller)进行调用之后的下一条指令地址作为返回地址压入栈内。这样调用函数(caller)的 eip(指令)信息得以保存:
3、Push EBP构建栈帧
再将当前的EBP寄存器的值(也就是调用函数的基地址)压入栈内,并将 EBP寄存器的值更新为当前栈顶的地址。这样调用函数(caller)的 EBP(基地址)信息得以保存。同时,EBP被更新为被调用函数(callee)的基地址:
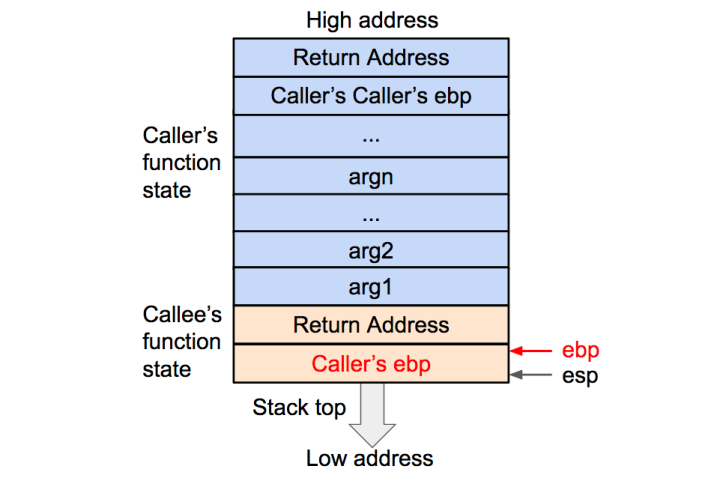
4、Push被调函数的局部变量等数据入栈
再之后是将被调用函数(callee)的局部变量等数据压入栈内:
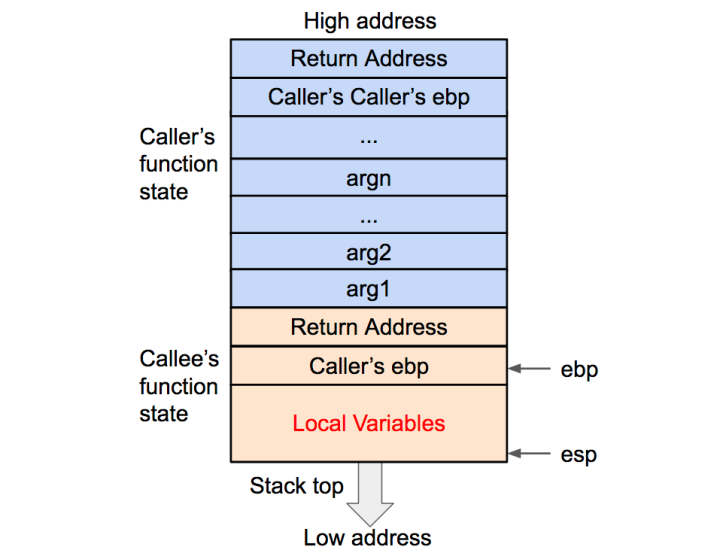
在压栈的过程中,esp 寄存器的值不断减小(对应于栈从内存高地址向低地址生长)。压入栈内的数据包括调用参数、返回地址、调用函数的基地址,以及局部变量,其中调用参数以外的数据共同构成了被调用函数(callee)的状态。在发生调用时,程序还会将被调用函数(callee)的指令地址存到 eip 寄存器内,这样程序就可以依次执行被调用函数的指令了。
函数调用结束时的栈变化
看过了函数调用发生时的情况,就不难理解函数调用结束时的变化。
变化的核心任务是丢弃被调用函数(callee)的状态,并将栈顶恢复为调用函数(caller)的状态。
1、Pop被调函数局部变量等数据出栈
首先被调用函数的局部变量会从栈内直接弹出,栈顶会指向被调用函数(callee)的基地址。
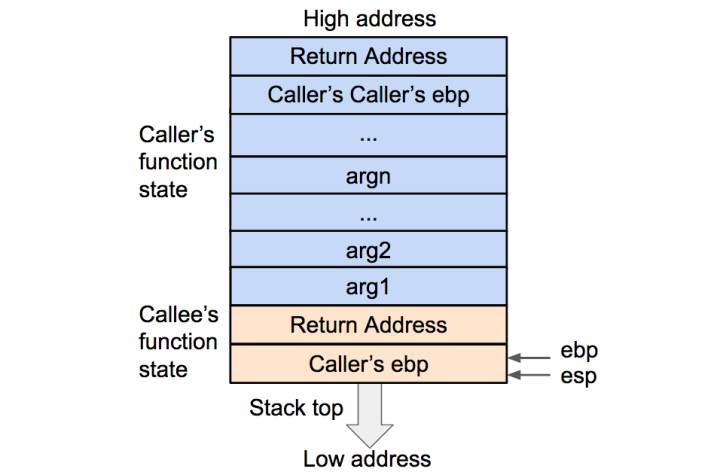
2、通过栈帧恢复调用函数基地址
然后将基地址内存储的调用函数(caller)的基地址从栈内弹出,并存到 EBP寄存器内。这样调用函数(caller)的 EBP(基地址)信息得以恢复。此时栈顶会指向返回地址。
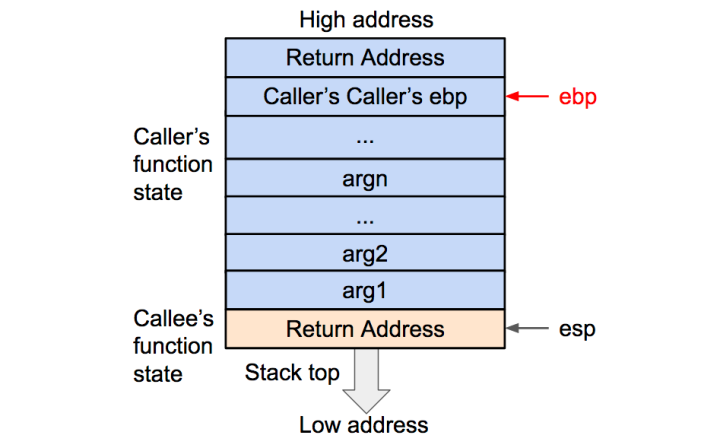
3、Pop调用函数下一条指令的地址到栈顶
再将返回地址从栈内弹出,并存到 EIP寄存器内。这样调用函数(caller)的 EIP(指令)信息得以恢复。
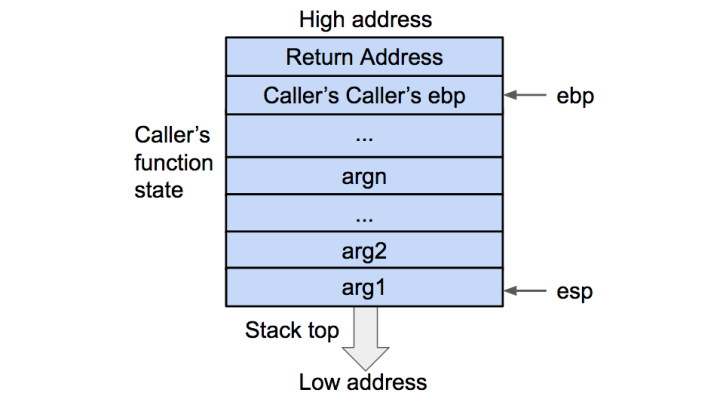
至此调用函数(caller)的函数状态就全部恢复了,之后就是继续执行调用函数的指令了,中间的被调函数的参数会直接被略过而返回到调用函数的指令中继续执行。
函数调用约定可参考之前的博文:函数调用约定
另外推荐两个学习函数调用栈的详细的教程: